Iskanje po spletu z Googlovim iskalnikom je postalo instinktivno dejanje. Vpišemo niz, na hitro pogledamo ponujene povezave in izberemo tisto, ki se nam zdi obetavna. Z Googlove strani pa je proces videti drugače. Z uporabnikovega računalnika dobi zahtevo za iskanje, iskalni niz, piškotek v njegovem računalniku, pa mu zagotovi še celo vrsto drugih podatkov. Algoritem za razvrščanje zadetkov (Page Rank) uredi rezultate iskanja glede na njihovo relevantnost (visoko uvrščenost, velik obisk ...) dodaten algoritem, ki za osnovo vzame osebne podatke uporabnika, pa jih prerazvrsti glede na uporabnikov interes (preference). Googlovo iskanje že nekaj časa ni več objektivno, temveč subjektivno v pravem smislu te besede. Isto iskanje vrne dvema uporabnikoma nekoliko različna rezultata. Podobne algoritme imajo v svoje storitve vgrajena tudi druga internetna podjetja, skupno vsem pa je, da delujejo bolje, če imajo na voljo veliko podatkov (dejansko teh ni nikoli dovolj). To je tudi glavni razlog, zakaj podatke podjetja zbirajo in hranijo. Uporabnik zaradi njih dobi boljšo storitev, pa tudi oglase, ki so jim bolj pisani na kožo. Napredni uporabniki spleta se algoritmov zavedajo, manj vešči pa ne, zato so manipulacije z njimi možne.
Google: »Vem, kaj te zanima.«

Poosebljanje je trend vseh spletnih iskalnikov, pomeni pa, da se rezultati iskanja prikrojijo za vsakega uporabnika posebej. Malo ljudi je opazilo, da se je splet 4. decembra 2009 spremenil. Tega dne je Google vključil prilagojeno iskanje vsem uporabnikom in od tedaj naprej ni nujno, da dobim za isti iskalni niz enake rezultate (oziroma po enakem vrstnem redu) kot vi. Na to vplivajo zgodovina iskanja, povezave, ki ste jih kliknili, in podobno. (Več o tem: http://tinyurl.com/dygqv4l).
Uporabniku prilagojeno iskanje deluje, tudi če niste vpisani z Googlovim računom, saj identifikacijska številka piškotka v uporabnikovem računalniku tega poveže z Googlovo zbirko podatkov. Če piškotka ročno sami ne izbrišete, je aktiven v računalniku 180 dni, lahko pa sami vplivate na prilagojeno iskanje tako, da v računu zahtevate izbris zgodovine iskanj. Z drugimi besedami, z brisanjem podatkov, na osnovi katerih algoritem odloča namesto uporabnika. Kako ta deluje, Google ne pove, zanašamo se lahko le na opazovanje, kar je storila skupina britanskih znanstvenikov. Ugotovili so, da se lahko rezultati iskanja razlikujejo med 10 do 50 odstotki. Tega pa ne počne le Google. Tudi Bing ima algoritem za prilagajanje rezultatov iskanj uporabniku.
Prilagojeno iskanje je nuja glede na vse večje število informacij v spletu, kar je še najočitnejše pri novicah. V svoji novičarski storitvi naj bi Google uporabljal tri algoritme. Dva naj bi spremljala bralne navade uporabnikov in rezultate primerjala med seboj s ciljem iskanja podobnosti, tretji pa naj bi analiziral novice, ki jih uporabnik prebira, in pogostost branja. Vsi algoritmi se znajo sproti učiti na podlagi novih podatkov, ki jih pridobijo. Naloga teh algoritmov pa je predvideti, kaj bo uporabnik kliknil, morda še preden bo o tem pomislil, in mu to »servirati na pladnju«.
Facebook: »Vem, kdo ti je všeč.«
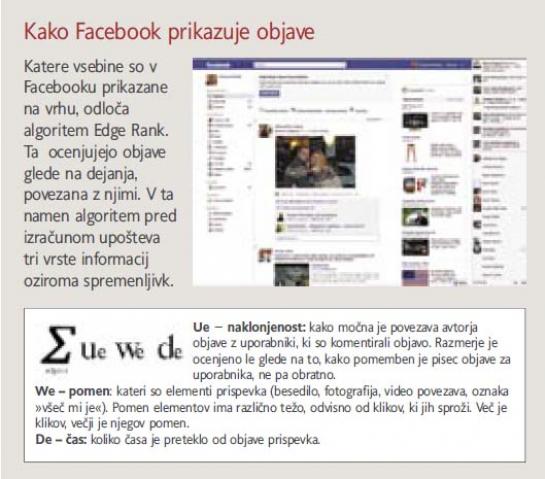
Družabna omrežja analizirajo povezave med uporabniki. Koliko podatkov ustvarijo uporabniki Facebooka, presega meje domišljije. Omrežje ima več kot 700 milijonov članov, ki ustvari bilijon ogledov strani na mesec (page view). V povprečju ima vsak član med 120 in 130 prijateljev, mesečno vsak 90-krat v omrežju kaj stori, kar v povprečni skupini uporabnikov pomeni skoraj 11 tisoč dejanj. In to kljub temu, da je povprečni uporabnik dnevno v omrežju aktiven manj kot eno uro. Kako naj uporabnik torej sledi, kaj so napisali, »lajkali«, komentirali, …. le njegovi prijatelji?
Verjetno je to nemogoče, če niste prilepljeni na zaslon računalnika ves čas in nestrpno spremljate, kaj se dogaja v omrežju prijateljev. Ima pa Facebook svoj algoritem EdgeRank, ki razvršča objave prijateljev glede na njihovo aktivnost in odloča, katere si uporabnik želi prebrati in kateri so tisti, ki ga sploh ne zanimajo. Če na primer prijatelj redno komentira objave uporabnika, ta pa njegove, to algoritmu pove, da gre za pomembno povezavo. Prav tako algoritem poskuša dojeti naravo objave: ali gre le za besedilo ali pa vsebuje tudi video povezavo, ki ima večjo težo, število komentarjev, kako pogosto član kaj objavi in podobno. Algoritem pa tudi določa s kom in kako bo uporabnik komuniciral, in odloča o družabnem uspehu uporabnika v omrežju. Zaradi načina delovanja nagrajujejo aktivno obnašanje, dejanja takih članov so v omrežju na vidnejšem mestu, hkrati pa kaznuje neaktivnost. Drugače povedano, pravila v družabnem omrežju oblikuje algoritem in člani, ki jih ne razumejo, so v izgubljenem položaju.
Gmail: »Odločam, kdo so prijatelji.«
Podoben algoritem, ki odloča, s kom bo uporabnik komuniciral, pozna tudi Gmail – to je funkcija prioritetnega poštnega predala. Če je vključena, poštna sporočila niso več urejena po datumu, namesto tega algoritem skuša ugotoviti, katero poštno sporočilo je pomembno, in tega prikaže na vrhu predala. Algoritem se odloča na podlagi družabne komponente, kako pogosto sta do zdaj komunicirala dva uporabnika, prav tako pa »skenira« telesa sporočila in v njih išče ključne besede, torej tiste, za katere oceni, da so za uporabnika pomembne (s tem pa je pomembno tudi poštno sporočilo). Odloča se tudi na podlagi podatka o tem, kako dolgo že traja redna izmenjava sporočil med dvema uporabnikoma, kdo je komunikacijo začel, upošteva pa tudi nastavitve poštnega predala. Algoritem sproti spremlja dogajanje v pošten predalu, primerja podatke uporabnika z globalnim modelom in se stalno prilagaja, saj se uči na podlagi na novo pridobljenih podatkov.
Aprila lanskega leta, je Gmail naredil še korak naprej. Ko uporabnik napiše poštno sporočilo, glede na poznavanje uporabnika in njegovih prijateljev iz imenika, predlaga, komu bi morda to sporočilo še poslal, ker bi ga morda zanimalo. Prav tako preverja, ali ni po pomoti sporočila poslal napačnemu prejemniku, saj zna iz analize prometa razločiti zasebne od poslovnih stikov. Po Googlovih podatkih naj bi bila zanesljivost 70-odstotna.
Amazon: »Vem, kaj ti je všeč.«
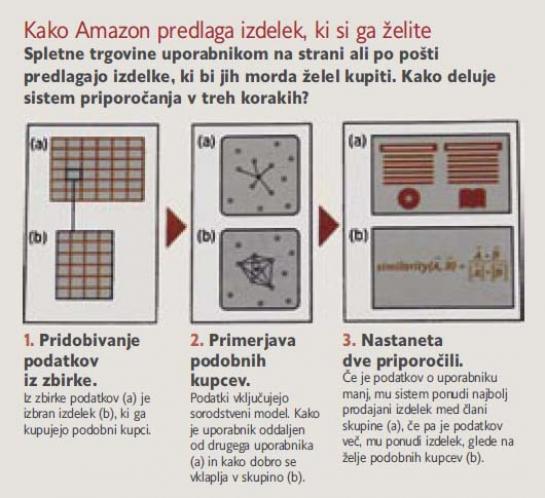
Vedeti, kaj bi lahko kupec še kupil, poleg tistega, kar je prišel kupit, je recept za uspeh spletnih trgovin. Amazon je pred desetimi leti uvedel algoritem za priporočanje izdelkov, ki je razvrščal izdelke v skupine po sorodnosti. Algoritem ni analiziral kupcev, temveč nakupe, in je iskal izdelke, ki jih kupci radi kupujejo skupaj. Pri tem se je zanašal na njihove ocene izdelkov v trgovini. Takratne tržne analize so kazale, da več kot polovica uporabnikov, ki pridejo v spletno trgovino kupit točno določen izdelek, pogosto radi odkrivajo še druge izdelke in kupijo tudi te. Algoritem, ki je priporočal izdelke, je Amazonu prinesel konkurenčno prednost pred drugimi spletnimi trgovinami. Prednost algoritma je v tem, da za priporočanje ne potrebuje podatkov o kupcih, če pa ima tudi te, če pozna kupčeve interese, potem so njegova priporočila toliko boljša. Danes podobne algoritme uporabljajo tudi drugi spletni trgovci, pa tudi spletni portal YouTube, moderni algoritmi pa analizirajo podatke o izdelkih in o kupcih, kaj ti počnejo na strani, podrobnosti katerih izdelkov pregledujejo, katere izdelke ocenjujejo, kaj so kupovali in podobno.
Algoritem, ki uporabnikom priporoči, kateri film bi ga morda zanimal, ima tudi spletna videoteka Netflix. Podatke o uporabnikih in filmih razvršča v tabeli po kategorijah, kot so žanri, ali so filmi resni ali zabavni, primerni za ženske ali moške in podobno. Rezultati analize so lahko presenetljivi. Otroške filme, kot je Čarovnik iz Oza, si dostikrat ogledajo ljudje, ki so gledali tudi triler Ko jagenjčki obmolknejo.. Algoritem analizira obnašanje uporabnike na strani (kaj iščejo, kaj berejo na strani), pa tudi s kakšno oceno so ocenili določene tipe filmov. Uporabnike poskuša uvrstiti v vedenjske modele, jih popredalčkati. Tako pa so lahko predlogi algoritma uspešnejši in uporabnik je voden v nakup novega izdelka ali v ogled filma.
Hote ali nehote puščamo v spletu podatke, iz katerih lahko algoritmi o uporabniku izvedo veliko, predvsem pa ga želijo profilirati, uvrstiti v določeno skupino ljudi, za katere ve, kako lahko z njimi manipulira. Cilj je vedno isti, prepričati ljudi, da nekaj storijo – kupijo izdelek, storitev ali si ogledajo spletni oglas. Delovanje algoritmov temelji na znanstvenih ugotovitvah, saj imajo globalna spletna podjetja dovolj denarja za financiranje znanstvenih raziskav. V tem pogledu se dosti ne razlikujejo od klasičnih velikih trgovskih centrov, ki imajo na primer stojnico za kruh, tega pa moramo vsi redno kupovati, čisto na drugem koncu trgovine, saj vedo, da je na poti do te dovolj priložnosti, da kupca prepričajo, da kupi še kaj. Najbolje nekaj, po kar ni prišel in česar sploh ne potrebuje!
Škrat na ramenu
Če kdo misli, da je za zaslonom računalnika anonimen, se krepko moti. Današnji splet je videti, kot da bi imel vsak uporabnik na rami škratka, ki več čas gleda, kaj ta počne, in to sporoča tistemu, ki ga je poslal sedet na ramo. Škratek je bajeslovno bitje, piškotek (cookie) pa njegova resnična zamenjava.
Po eni strani se vedno razburjamo, ko država napove cenzuro in filtriranje interneta, ne zavedamo pa se, da so za odprtost interneta večja grožnja zasebne korporacije, ki jih (skoraj) nihče ne nadzira. Vprašanje pa je tudi, ali bi nadzor in regulacija sploh lahko dosegla svoj namen. Regulacija zaradi svoje narave hitro preide v eno od dveh skrajnosti. Lahko postane pokroviteljska zaradi pretirane zaščite ljudi ali neživljenjska, ko so pravila lepo napisana na papirju in zajemajo vse mogoče situacije, vendar jih je v praksi nemogoče uveljaviti.
Prav tako regulacija stavi na prepričanje, da so ljudje po naravi neumni. Pa niso, pod pogojem, da se jim da razmišljati. Iz tega pa se lahko rodi pretiravanje glede pomena kakšne storitve v internetu. Kot pravi novinarski kolega Kučič: »Facebok je poslovna ideja, ki izkorišča infrastrukturo, internet, naš trenutni odnos do zasebnosti, našo trenutno izkušnjo, da se nam ni zgodilo nič slabega, in naše trenutno nezavedanje, da je vse javno. To je Facebook, in nič več!«. Kaj želimo s tem povedati? Ko se daje čemu prevelik družbeni pomen, se hitro najdejo načini upravičevanja stvari, ki jih počne! Dejstva so zelo preprosta. Facebook in drugi zbirajo osebne podatke, služijo na njihov račun, pa če nam je to prav ali ne. Krivi smo sami, ker jim prostovoljno dajemo vse, kar si želijo. Kučič je uporabil še eno primerjavo. »Če bi na cesti pristopila oseba, vam pod nos pomolila podrobno anketo in prosila, da jo izpolnite, bi jo verjetno nekam poslali. Ko vas to prosijo v spletu, večina uporabnikov rade volje ustreže.«
Konec okvirja
Moj mikro, januar 2012 | Marjan Kodelja