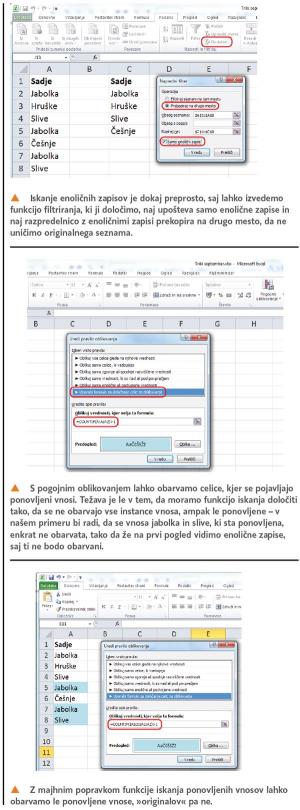
Najprej si oglejmo primer, ko bi radi z našega seznama odstranili vse ponovljene vnose (namenoma pišemo vnose, in ne vrednosti, saj običajno ne gre za števila, ampak besede, datume ali kaj podobnega, seveda pa lahko gre tudi za števila). Postopek je dokaj preprost, saj lahko uporabimo kar malce dodelano funkcijo filtriranja. Vzemimo, da imamo neki preprost seznam sadja, v njem pa so nekateri vnosi ponovljeni, radi pa bi seznam vnosov brez ponavljanja, saj nas zanima recimo število različnih oziroma enoličnih vnosov. Najpreprostejši način je, da izberemo seznam (na sliki v našem primeru je to A1:A8), nato iz opravilne vrstice Podatki v razdelku Razvrsti in filtriraj izberemo Dodatno, v okencu, ki se odpre, pa določimo, naj se seznam prekopira na drugo mesto, z miško ali ročno določimo to mesto (v našem primeru C1:C8), nato pa vključimo še možnost Enolični zapisi. V stolpcu C se bo pojavil seznam, ki bo podoben osnovnemu, le da v njem ne bo ponovljenih zapisov. Pri tem je treba paziti, da ima stolpec naslov, v našem primeru je to »sadje«. Če naslova ne damo, bo Excel za naslov uporabil prvo vrstico, kar ne bo v redu, saj se bo v novi razpredelnici ta naslov spet pojavil in bo videti, kot da je en vnos še vedno podvojen. Če bi v našem primeru pozabili na naslov, bi bil filtriran seznam tak, da bi na prvem mestu bil zapis »jabolka«, nato bi sledilo drugo sadje, med katerim bi se jabolka ponovila še enkrat. Če pa damo stolpcu naslov, se to ne zgodi.
Kaj pa, če ne želimo razpredelnice z enoličnimi zapisi, pač pa bi radi, da se v originalnem seznamu le obarvajo ponovljeni vnosi? V tem primeru bomo uporabili nekaj, o čemer smo v tem prispevku že pisali – pogojno oblikovanje, pri čemer bomo uporabili funkcijo COUNTIF. Postopek je dokaj preprost. Najprej izberemo obseg vnosov, v našem primeru je to območje A2:A8. Nato izberemo Pogojno oblikovanje, v njem pa izdelavo novega pravila. V seznamu izberemo Uporabi formulo za določanje celic za oblikovanje, v polje funkcije pa vpišemo izraz:
=COUNTIF(A:A;A2)>1
Nato seveda določimo še oblikovanje, recimo takšno, kjer se celica s podvojenim vnosom obarva modro. Težava metode je v tem, da se obarvajo vse instance vnosa, ne pa ponovljene vrednosti. V našem primeru se obarvajo vsi vnosi »jabolka« in »slive«, saj se oba vnosa v seznamu ponovita. To je v nekaterih primerih sicer lahko koristno, večinoma pa bi radi, da se obarvajo le ponovljene vrednosti, ena instanca pa ostane neoznačena. Tako lahko namreč hitro ugotovimo, kateri vnosi so enolični in kateri ponovljeni.
Kako torej seznam označiti tako, da bodo obarvani le ponovljeni vnosi? Preprosto, formulo pogojnega oblikovanja spremenimo tako, da se bo glasila:
=COUNTIF($A$2:$A2;A2)>1
Kaj pa, če želimo poiskati podvojene vrednosti čez več stolpcev? Recimo, da imamo dva stolpca. V prvem so imena, v drugem priimki, nas pa zanimajo osebe, ki so v tem seznamu podvojene. V tem primeru seveda ne moremo uporabiti enake funkcije kot pri sadju, saj se utegne zgoditi, da imamo v seznamu osebe, ki imajo enako ime in različen priimek in obratno. V tem primeru je najbolje, če uporabimo funkcijo združevanja vsebine polj, šele nato pa poiščemo dvojnike. Pa si oglejmo primer. Imamo seznam, podoben tistemu na sliki. V prvem stolpcu imamo imena, v drugem priimke, radi pa bi ugotovili, katera imena so podvojena. Pri tem imamo osebe z enakimi imeni (Jože Horvat in Jože Malek) in osebe z enakimi priimki (Peter Murko in Miha Murko). Kako ugotoviti, katera imena so podvojena?
Zadevo bomo izvedli po korakih, da boste lažje spremljali, za kaj gre. Najprej bomo v stolpcu D imena in priimke združili. Pri tem bomo uporabili preprosto funkcijo »&«. V polje D2 vpišemo:
=A2&B2
Vidimo, da se pojavi vnos JožeHorvat, torej brez presledka med imenom in priimkom. Videti je čudno, vendar za naše potrebe popolnoma dovolj. Sicer bi lahko vstavili še presledek tako, da bi funkcijo oblikovali kot =A2&" "&B2, vendar s tem ne bi naredili ničesar koristnega za rezultat, ki ga iščemo. Zdaj celico prekopiramo navzdol tako, da združimo še ostala imena in priimke.
Zdaj pa se lahko lotimo iskanja ponovljenih zapisov. Vzemimo, da tokrat podvojenih zapisov ne bomo barvali, pač pa bomo v sosednji stolpec vpisali besedico »Podvojen«, če se bo zapis ponovil. Postavimo se v celico E2 in vanjo vpišemo formulo, podobno tisti pri sadju:
=IF(COUNTIF(D$2:D$9;D2)>1;"Podvojen";"")
Funkcija je preprosta – preišči področje D2:D9, in če najdeš dvojnik, vpiši besedo »Podvojen«, sicer naj bo polje prazno. Slednje, torej prazno polje, moramo vpisati zato, ker bo Excel sicer v polje vpisal FALSE, saj pogoj ne bo izpolnjen. Kot vidimo na sliki, je program našel podvojen vnos in to označil, kot smo želeli.
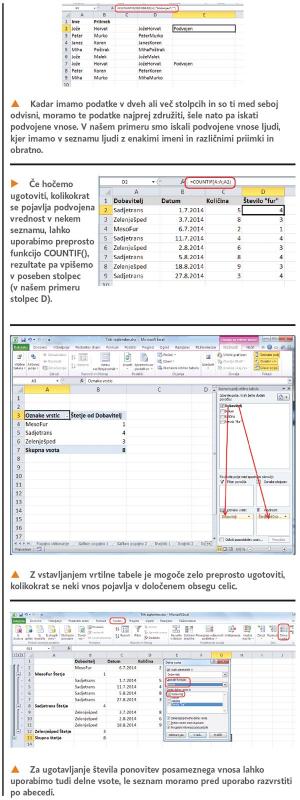
Zdaj pa zadevo še malce zapletimo. Kaj pa, če želimo ugotoviti, kolikokrat se neki vnos v seznamu ponovi? Vzemimo primer, ko smo spremljali dobavo nekih izdelkov in nas zanima, kolikokrat nam je dobavitelj blago pripeljal oziroma po domače, koliko »fur« mu moramo plačati. Vse skupaj smo vstavili v preprosto razpredelnico, kjer imamo v prvem stolpcu ime dobavitelja, v drugem datum dobave, v tretjem pa količino blaga. Pravzaprav nas druga dva stolpca v našem primeru ne zanimata, saj nas zanima le, kolikokrat se posamezni dobavitelj pojavi v stolpcu A. V ta namen na koncu razpredelnice dodamo še en stolpec, v našem primeru je to stolpec D, in ga poimenujemo, recimo »število fur«. Postavimo se v polje D2 in vpišemo že znano funkcijo:
=COUNTIF(A:A;A2)
V našem primeru se v celici prikaže številka 4, saj se dobavitelj Sadjetrans v našem seznamu pojavi štirikrat. Zdaj celico kopiramo navzdol in prikazale se bodo številke tudi za druge dobavitelje.
A ta metoda ima nekatere slabosti. Prva je ta, da se številke v stolpcu D ponavljajo vsakič, ko je v stolpcu A dobavitelj, na katerega se nanaša. Zadevo bi lahko rešili tako, da formulo pač prekopiramo čez prve tri celice, saj vemo, da so dobavitelji trije, hkrati pa se v stolpcu A pojavijo drug za drugim. To bi sicer šlo, a je nepraktično, saj ni nujno, da bodo dobavitelji prihajali drug za drugim. Kaj, če pride najprej prvi, potem drugi, pa spet prvi in šele nato tretji? V tem primeru rešitev ne bo delovala. Poleg tega moramo vedeti, koliko dobaviteljev imamo, kar se lahko spreminja, in če o spremembah nismo obveščeni, ne bomo vedeli, čez koliko vrstic naj rezultat kopiramo. Tretja težava je v tem, da se pregleduje celoten stolpec A, in če se po naključju zgodi, da imamo kje pozneje še enkrat vpisanega kakšnega od dobaviteljev, verjetno v čisto drugem kontekstu, se bo prištel tudi ta, kar seveda ni v redu.
Torej si je za kompleksnejše sezname treba izmisliti nekaj drugega. Recimo nekaj »znanstvenega«, kot je tako imenovana Vrtilna tabela. Kaj je to, ne bomo na dolgo in široko razlagali, saj bi za to potrebovali ne le poseben članek, ampak nekaj številk celotnega Mojega mikra. Zato na kratko povejmo, da gre za možnost različnega prikaza podatkov iz različnih razpredelnic. V našem primeru se bo dokaj nazorno pokazalo, kako »pametne« so vrtilne tabele. Izberemo katero koli polje v stolpcu A, torej v seznamu dobaviteljev, nato pa iz razdelka Vstavljanje izberemo Vrtilna tabela. Excel nam bo ponudil precej možnosti, a v našem primeru nas te ne zanimajo in jih le potrdimo. Prikazalo se bo malce nevsakdanje okno oziroma nov delovni list, kjer nas zanima dogajanje na desni strani zaslona. Tam bomo imeli seznam polj (Dobavitelj, Datum, Količina …), kot jih imamo na našem seznamu, spodaj pa še štiri okenca. Nas zanima le polje Dobavitelj, zato ga označimo (v kvadratku se bo pojavila kljukica) in ga povlečemo najprej v okence Oznake vrstic, nato pa še v okence Vrednosti. Na delovnem listu se bo pojavila razpredelnica, v kateri bodo zapisani vsi dobavitelji po enkrat, zraven pa še število ponovitev, kar predstavlja število »fur«, ki so jih opravili. Dokaj elegantno in preprosto.
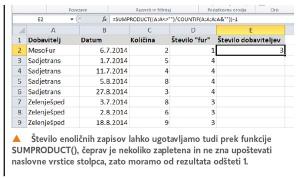
Obstaja pa še ena zanimiva rešitev, ki jo lahko izvedemo s pomočjo tako imenovane delne vsote. Pri tem sicer moramo podatke najprej razvrstiti po abecedi, a to pogosto tako ali tako naredimo, preden gremo šteti, kolikokrat se neki vnos ponovi.
Torej, najprej se postavimo v stolpec A in iz okvirčka Urejanje opravilnega traku Osnovno izberemo Razvrsti in filtriraj, nato pa izberemo razvrščanje od A do Z. Podatki bodo razvrščeni po abecedi in posamezni dobavitelji bodo zapisani skupaj. Zdaj izberemo opravilni trak Podatki, v njem pa v okvirčku Oris funkcijo Delna vsota. Prikazalo se bo okence, v katerem je treba izbrati nekaj stvari. Najprej s seznama Uporabi funkcijo izberemo Štetje, nato v okencu Dodaj delno vsoto k izberemo le vnos Dobavitelj. In to je vse. Ko naš izbor potrdimo, se bo naš razvrščeni seznam malce spremenil, in to tako, da se bo med posamezne dobavitelje vrinila še ena vrstica, v kateri bo zapisano, kolikokrat se je ta dobavitelj pojavil na seznamu, na koncu pa bo prikazano še skupno število prikazov, torej število »fur«, ki so jih izvedli vsi dobavitelji skupaj. V nekaterih primerih bolj uporabno kot prejšnje rešitve.
Še ena možnost, ki se nam pojavlja v povezavi s ponovljenimi vnosi, je ugotavljanje števila enoličnih zapisov, v našem primeru torej ugotavljanje števila dobaviteljev. Čeprav je problem iskanja enoličnih zapisov že zelo star, Excel še zdaj (vsaj jaz ne vem zanjo) ne vključuje funkcije, ki bi znala prešteti enolične zapise. Zato je treba iti malce naokoli in uporabiti funkcijo SUMPRODUCT(). Ta se bo malce zapleteno glasila:
=SUMPRODUCT((A:A<>"")/COUNTIF(A:A;A:A&""))-1
Ker je funkcija dokaj zapletena, je ne bomo na dolgo razlagali. Več o njej seveda lahko najdete v pomoči Excela, na tem mestu povejmo le, zakaj imamo na koncu formule odšteto število ena. To pa zato, ker imamo v našem seznamu na vrhu tudi naslov stolpca, torej »Dobavitelj«. V tem primeru, v nasprotju s tistim, o čemer smo govorili na začetku pri seznamu sadja, ko je bil naslov obvezen, bo Excel tudi naslov obravnaval kot vnos, kar je seveda narobe, zato moramo naslovno celico odšteti oziroma izvzeti iz štetja.
Moj mikro, september – oktober 2014 | Miha Gradišnik |