Iz zapisanega vidimo, da so nadzorne vsote namenjene predvsem odkrivanju napak, ne pa njihovemu odpravljanju. A obstajajo načini, kjer je mogoče nadzorne vsote uporabiti tudi kot sistem popravljanja napak. Najpreprostejši tovrstni sistem je 2D-pariteta. Oglejmo si, kako deluje na primeru 16-bitnega števila, recimo 9234522314728354. Število najprej razdelimo na štiri dele in ga zapišemo v matriko velikosti 4 x 4, kot vidimo na sliki na levi strani. Naslednji korak je, da izračunamo nadzorne vsote posamezne vrstice in stolpca. Pri tem vsoto recimo dobimo tako, da upoštevamo le število enic v vsoti, kot vidimo na sliki v sredini. Vsota prvih štirih številk je 18, zato kot nadzorno število vpišemo 8. Postopek ponovimo za vse vrstice in stolpce in dobimo matriko, kot je vidna na sliki v sredini. Zdaj lahko naše število zapišemo kot 24-bitno število, saj šestnajstim bitom dodamo še nadzorno vsoto tako, da po vsaki vrstici vpišemo nadzorno številko, nadzorno številko stolpcev pa zapišemo na koncu. Naše število se torej zdaj glasi 923485223214724835403173 (krepko so označene številke iz nadzornih vsot).
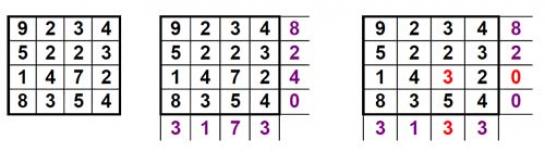
Takšno število se zdaj lahko prenese. Naslovnik lahko število »razpakira« in preveri, ali so vse nadzorne številke prave. Če so, lahko iz 24-bitnega števila izlušči želeno 16-bitno, nadzorne pa izbriše. Če pride do napake, pa nadzorne vsote ne bodo več prave. Vzemimo, da je bilo pri prenosu nekaj narobe in se enajsta števka (tretja številka v tretji vrsti) namesto 7 glasi 3, kot je to vidno na desni strani slike, kjer je napačna številka obarvana rdeče. Ker se točno ve, kateri nadzorni vsoti sta napačni, v našem primeru vsota v tretji vrstici in tretjem stolpcu, sistem takoj ve, da je nekaj narobe s številko, ki leži na križišču te vrstice in stolpca. Napaka je torej odkrita. In ne le to, da obstaja, ampak tudi točno mesto, kjer se nahaja.
Kaj pa odpravljanje? To je dokaj preprosto. V obeh primerih je nadzorna vsota za 4 manjša od tiste, ki bi morala biti, zato je jasno, da mora biti pravo število za 4 večje od obstoječega, kar je seveda 7, in napaka je odpravljena.
Sistem je dokaj zabaven, saj nam daje možnost natančnega ugotavljanja tako napak v recimo 16-bitnem številu kot tudi v nadzornih vsotah. Če je na primer nadzorna vsota v vseh vrsticah pravilna, v stolpcih pa ne, je nekaj narobe z nadzorno vsoto, ne pa s številom samim. Opisana metoda se sicer v praksi zelo redko uporablja, saj so razvite bolj učinkovite, je pa dober nazoren prikaz, kako se napake odkrivajo in popravljajo. In do opisanega je prišel omenjeni Richard Hamming, iz njegovih ugotovitev in zamisli pa je nastalo precej raznovrstnih načinov odkrivanja in popravljanja napak, imenovanih Hammingove kode.
Pa si oglejmo, kako nastane Hammingova koda (7,4). Oznaka pomeni, da bomo zgradili kodo, ki bo vsebovala sedem bitov, od katerih bodo štirje nosilci podatkov. Za lažje spremljanje bomo postopek zapisali v korakih.
1. Posamezne bite številke bomo zapisali z zaporednimi števili 1, 2, 3, 4, 5, 6 in 7 in jih zapisali v binarni obliki, torej 1, 10, 11, 100, 101, 110 in 111.
2. Vsa ta binarna števila, ki imajo v sebi le eno enico, bodo paritetni biti (P), ostala pa podatkovni biti (D). Naši paritetni biti bodo torej 1, 2 in 4 oziroma 1, 10 in 100, podatkovni pa 3, 5, 6 in 7.
3. Zdaj bomo izračunali paritetne bite. Te bomo dobili tako, da bomo pri njihovem izračunu uporabili podatkovne bite. Paritetni bit P1 bomo izračunali s pomočjo bitov, ki imajo na koncu enico (1, 11, 101 in 111, torej iz števil 1, 3, 5 in 7), paritetni bit P2 iz bitov, ki imajo enico na predzadnjem mestu, torej iz 10, 11, 110 in 111, torej iz 2, 3, 6 in 7, P3 pa iz bitov, ki imajo enico na tretjem mestu z desne, torej 100, 101, 110 in 111 oziroma 4, 5, 6 in 7.
Kako bi na primer zapisali binarno število 1010 s pomočjo opisane Hammingove kode? Število najprej zapišemo v obliki:
x x 1 x 0 1 0
Oznake x določajo paritetne bite, s katerimi bomo opremili število. Najprej določimo paritetni bit P1. Zapisali smo, da ga bomo dobili iz bitov 1, 3, 5 in 7. Ker prvega še nimamo, bomo uporabili 3, 5 in 7. V našem zapisu xx1x010 so na tretjem, petem in sedmem mestu biti 1 0 in 0, kar da pri sodi pariteti enico. Paritetni bit P2 izračunamo iz 3, 6 in 7, kar da 1, 1 0 in je zato 0, bit P3 pa izračunamo iz 5, 6 in 7 (štirice nimamo), kar je 0, 1, 0 in je pariteta torej 1. Naše 7-bitno število se bo zdaj glasilo:
1 0 1 1 0 1 0

Zdaj pa si oglejmo, kaj se zgodi, če pride do napake. Vzemimo, da je bil prenesen niz 1011110, torej se je napaka pojavila le v enem bitu. Če na tem številu izvedemo Hammingovo kodiranje na podatkovnih bitih (3, 5, 6 in 7), ugotovimo, da dobimo število 0010110, kar pomeni, da je nekaj narobe. A vidimo lahko še nekaj več. Če primerjamo paritetne bite, vidimo, da sta P1 in P3 (prvi in četrti bit z leve) napačna, P2 (drugi z leve) pa pravilen. Skupni bit pri izračunu paritetnih bitov P1 in P3, torej napačnih, je bit 5, kar pomeni, da mora biti napaka v njem. In ker je popravek mogoč le iz enice v ničlo, je napaka kaj hitro odpravljena.
Pri Hammingovi kodi gre torej tako za odkrivanje kot tudi za popravljanje napak. Matematični izračuni so pokazali, da so Hammingove kode eden najučinkovitejših, če ne celo najučinkovitejši način odpravljanja enobitnih napak pri prenosu podatkov.
Hammingova koda se zadnje čase manj uporablja, saj so bili razviti bolj učinkoviti algoritmi, kot je na primer Reed-Solomonove kode, ki so primerne tudi za večkratne napake. Se pa Hammingove kode še vedno uporabljajo pri delovnih pomnilnikih (RAM), kjer se doda še en paritetni bit, ki se izračuna iz preteklih sedmih. Ta razširjena Hammingova koda je znana pod imenom SECDED (Single Error Correction Double Error Detection), poleg tega pa je namesto kode 7,4 uporabljena koda 72, 64, torej je koda zapisana z 72 biti, od katerih je 64 bitov nosilcev podatkov, 8 pa paritetnih.
Reed-Solomonova koda
Hammingove kode so sicer dobre, niso pa primerne za odkrivanje več napak znotraj prenosa. Zato sta Irving S. Reed in Gustave Solomon razvila nov način odkrivanja in popravljanja napak, ki je tega sposoben. Metoda temelji na polinomih nad končnimi polji, kar je dokaj zapletena matematika, ki seveda presega okvire tega prispevka. A za najbolj radovedne bomo poskusili razložiti vsaj zamisel, ki leži za tem. Simbole v podatkovnem toku si predstavljajmo kot koeficiente polinoma. Tak polinom se razišče z več vhodnimi vrednostmi, kot je njegova stopnja. Razmerje med vhodnimi in izhodnimi vrednostmi predstavlja razširjen sistem vrednosti, iz katerih lahko prejemnik izlušči oziroma interpolira originalni polinom in iz njega najde ustrezne koeficiente. Sliši se zapleteno, a zadeva deluje. RS-koda, kot se pogosto imenuje, se uporablja v sistemih shranjevanja podatkov, kjer želimo zmanjšati vpliv napak na medijih za shranjevanje, ki imajo za posledico večkratne napake. Koda RS se je izkazala za izredno učinkovito tudi v primerih do hkratnih napak na 4000 bitih, kar je nekako ekvivalent 2,5-milimetrske poškodbe na trdem disku. RS-kodo uporabljajo tudi nekateri sistemi branja črtne kode in kode QR, saj omogoča branje tudi poškodovanih kod, uporablja pa se tudi za vesoljske komunikacije za zagotovitev prenosov podatkov brez napak.
Moj mikro, junij 2012 | Miha Gradišnik |